
UoPeopleのCS2203の受講が終わりました。無事に単位も取得できたので、データベースのコースで個人的に要点だと思った部分をまとめます。
前提として、筆者はリレーショナルデータベースの操作はできるがアカデミックにデータベースのお勉強をしたことがない人間です。このコースで高得点を取得するために必要となるトピックとその解説を書いています。
英語で何をどう呼ぶか
抽象データモデルを考える時
| Attribute name | Type | Domain | Optional |
| ID | Unique identifier | Text | No |
| NAME | Composite attribute | Text | No |
| Single valued attribute | Text | Yes | |
| PET_NAME | Multi-valued attribute | Text | Yes |
| ADDRESS | Composite attribute | Text | Yes |
| ANUAL_SALARY | Single valued attribute | Number | Yes |
| MONTHLY_SALARY | Derived attribute | Number | Yes |
Attribute:属性
データの項目名です。
Type:データタイプ
データの形です。上の表では「ドメイン(※後述)」が全て「テキスト」だけれどデータタイプの異なるものの一例を集めてみました。
- Unique identifier:IDです。データを特定できる、他のデータと重複しない値を持つ項目
- Composite attribute(複合属性):「名前」は「名字」と「名前」に、「住所」は「国」「都道府県」「市」「町」…と複数に分割でき、それらの複数の要素を使って1つの情報となっています。このように複数の要素で1つのデータになるものです。
- Single valued attribute/ Simple Attribute(単一属性):上の表では「メールアドレス」がこれに当たっています。筆者の意見的には「@」以降のドメインと分割することもできないか?とは思いますが、まぁ実質メールアドレスを「@」前後で分けて保存している会社や組織はなかなかないと思います。つまり、1つであり、分割することのできないデータのこと。例えば、国名のみを集めたデータがあるとしたら、Single valued attribute。同様に、「動物データ」を作った時の「動物名」とか、「植物データ」を作った「植物名」とか、「図書館の本データ」の「本のタイトル」がこれにあたります。Composite attributeで「名前」を「名字」と「名前」を分けたように、「本のタイトル」を「何かA」と「何かB」に一律分割することはできませんよね。
- Multi-valued attribute(複数値属性):上の表では「ペット名」がこれです。ある1人の著者は、ペットを1匹飼っているかもしれないし、複数飼っている可能性もありますよね。1人の著者に対して、複数の値が入り得る(この著者は犬のチョコと猫のきなことウサギのとんすけを飼っているかもしれない!)
- Derived attribute(派生属性):この項目は、抽象データモデルに項目として登場しますが、実際の論理テーブルには存在しないことになります。理由は、他の項目によって特定が可能なデータだからです。上の表では、年収(ANNUAL_SALARY)項目と月収(MONTHLY_SALARY)項目がありますが、月収は「年収/12」で求めることができます。すなわち、論理テーブルは月収項目を保持する必要がない、ということになります。

ドメインとは何か?
リレーショナルデータベースについて話すときの「ドメイン」は「定義域」と訳されます。その項目が取り得る値の範囲のことで、「性別」のデータであれば「男、女、そのほか」がドメインとなります。「名前」の場合は数えきれないパターンがありますが、いづれも文字で表されるので「テキスト」となります。「データ型(=type)」とドメインは同じと考えて良い、という説明も多く見られます。
以下のサイトの画像が、英語で抽象テーブルの各要素をどのように呼ぶのかわかりやすく説明しています。

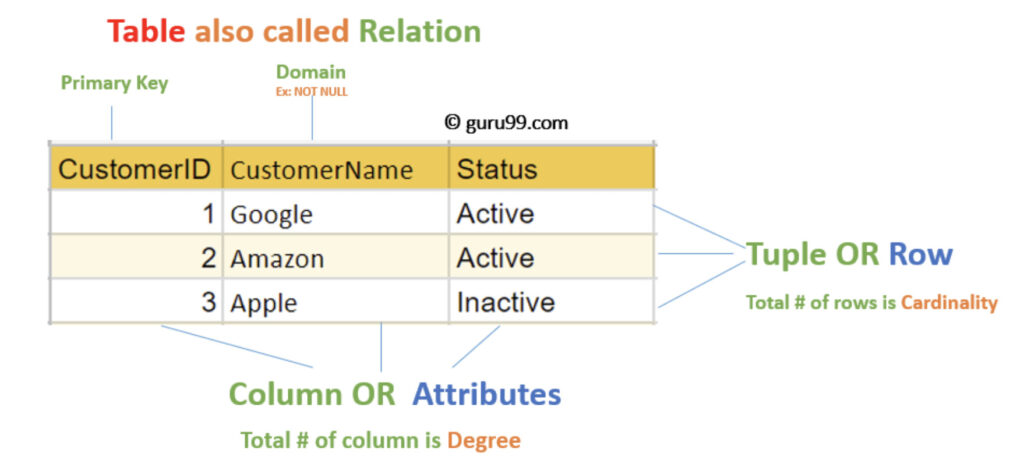
Candidate key(候補キー)とは
データを特定できる項目のこと。プライマリーキーは候補キーの中から選択して使います。
データベースに関わる役職の種類←Graded Quizにでた
- Data Architect(データアーキテクト):データ管理に関する組織の既存のニーズと将来のニーズをサポートするアーキテクチャを設計する責任を負っています。データベース、データ統合、データへのアクセス手段などを網羅しなければならない。データ統合、そしてデータを入手するための手段を網羅する必要がある。企業データ標準を設定することで、その目標を達成する。データモデラーとも呼ばれる。しかし、データモデルを作成することよりも多くのことを行う
- 論理データモデリング
- 物理データモデリング
- データ戦略および関連ポリシーの策定
- ビジネス情報ニーズに対応した機能・システムの選択
- Database Architect(データベースアーキテクト):データアーキテクトと似た仕事をしますが、もっとデータベース寄りの仕事を担当します。SLAの作成をしたり、経営陣から要件を聞き出して文書化したりします。
- Database Administrator (データベースアドミニストレーター)(DBA):データベースのメンテナンス、パフォーマンス、完全性、セキュリティに責任を持つ。さらに、計画、開発、トラブルシューティングなどの役割も求められます。仕事は組織やポストに関連する責任のレベルによって異なります。純粋なメンテナンスのみである場合もあれば、データベース開発に特化した仕事である場合もあります。
- Application Developer(アプリケーションデベロッパー):SQLを使って実際にデータベースを触る人です。
Cardinality(カーディナリティ)とは
あるデータ項目について、その項目に入りうる値のばらつき。ばらつきが高い場合(色々な値が入りえる)「カーディナリティが高い」。ばらつきが低い場合、例えば「性別」項目は「男、女、その他」のどれかしか入り得ないとしたら、「カーディナリティが低い」。
抽象データモデルのドメインが論理テーブルのお話になるとカーディナリティに当たる感じでしょうか。

ER図の表記法
基本的事項ですが、あらためてカーディナリティの表現を確認しておきましょう。
- 1:1なのか
- 1:Nなのか
- N:Mなのか
- 0も許可されるのか
以下の記事が丁寧にER図の表記をまとめています。

Normal Forms(データベース正規化)
簡単理解
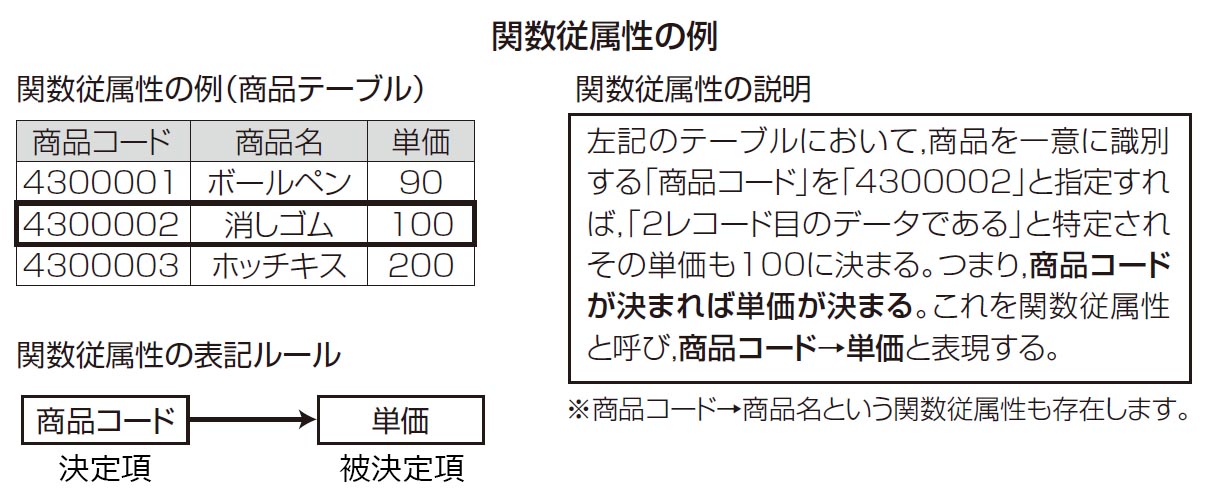
関係従属(Functional Dependency)
Aの値が決まるとBの値が決まる時、Bの値はAの値に依存する。
例:人の名前と誕生日をデータとして持っている場合、A君の誕生日はB。
First Normal Form (1NF)(第一正規形):必要な情報を、重複あってもいいから1つの二次元な表(縦と横に軸を取った、いわゆる普通の「表」)に抜け漏れなくデータを全マス埋めた形(Null値あっていいので、値がないマスは埋めなくていいが、埋められるところは全部埋める。「1つ上の行と同じ値だから埋めなくていいや」とかなし。
Second Normal Form (2NF)(第二正規形):データを特定するprimary keyが複数ある場合、キーの1部から紐づいて値が決まる部分を別entityに切り分けた後の形。また、第一正規形は当然満たす。
Third Normal Form (3NF)(第三正規形):entityの中で、primary keyではないいづれかの要素にぶら下がる形で(依存して)値が決まる要素を、その依存元と一緒に別entityに切り分けた後の形。切り分け元entityには依存元の要素だけ残し、依存している要素は残らない。また、第二正規形は当然満たす。
詳細理解
関数従属性:ある列の値 X が決まると同時に、別の列の値 Y が自動的に決まるとき、Y は X に関数従属であるといいます。Y が X に関数従属であるとき、X → Y と表記します。
推移的関数従属性:ある関数従属関係から、新たな関数従属関係が得られるような場合、推移的関数従属性を持つといいます。X → Y 及び Y → Z の関係があるとき、X → Z は推移的関数従属性を持ちます。
正規形まとめ
| 第一正規形 | ・繰り返しの項目を持たない。 |
| 第二正規形 | ・第一正規形の条件を満たす ・すべての非キー属性が候補キーに完全関数従属する。 |
| 第三正規形 | ・第二正規形の条件を満たす。 ・すべての非キー属性が候補キーに推移的関数従属しない。 |
| Boyce-Codd Normal Form (BCNF)(ボイスコッド正規形) | ・すべての列が主キーに完全関数従属で、他に完全関数従属関係がないもの |
そのほか要点まとめ
| 候補キー | 特定の1行を確定できる1つもしくは複数の項目の組合せ。 候補キーの値に、Null(空)のデータは不可。 |
| 主キー | 候補キーの一つを主キーと呼ぶ。 |
| 関係関数従属 | Aが決まると、Bが一つに決まる事。 A -> B と書く |
| 部分関数従属 | 候補キーの一つに関係関数従属している事。 |
| 完全関数従属 | すべての非キー項目が候補キーに部分関数従属していないこと。 |
| 推移的関数従属 | A -> B -> C の時、CはAに推移的関数従属している。 |

Lossless and Lossy Decomposition(ロスレス分解、ロッシー分解)
ロスレス分解:データベース正規化により情報が失われる情報が生まれないように正規化すること
ロッシー分解:失われるデータのあるデータベース正規化
パッと見て明らかな通り、Lossyは良くない。

Closure of a set of attribute(属性の閉包)とは?
別記事にまとめました。
一言で説明すると、「Aの閉包」とはデータ項目Aの値に依存して決まるデータ項目のことです。

Anomalyとは?
Anomalyは「異常」という意味で、データベースでは以下のように使用されます。
更新不整合(Update Anomaly)
データ更新しようとするとうまくいかないケース。
修正不整合(Modification Anomaly)
何かデータを更新したい時、そのデータを更新するなら同時に更新すべきデータがあるのに、それを行わなかったケース。
挿入不整合(Insert Anomaly)
データを挿入する時、そのデータではひもづく元データがないなど、正常に挿入ができないケース。
削除不整合(Delete Anomaly)
そのデータを削除するならひもづく関連データも消さないと変なデータが残ってしまうんだけど、そうしてしまったケース。
日本語では「アノマリ検知(Anomaly detection)」といった風に使われるんですね。
アノマリ(Anomaly)は日本語で「異常」を意味します。 アノマリ検知は異常検知とも呼ばれます。平常値のパフォーマンス値の範囲から外れた挙動を示した場合を「異常」として扱います。
https://www.manageengine.jp/products/Applications_Manager/application-anomaly-detection.html
surrogate key(サロゲートキー)
「代理キー」「代替キー」「代用キー」と言われます。
サロゲートキーとは、データベースのテーブルの主キーとして、自動割り当ての連続した通し番号のように、利用者や記録する対象とは直接関係のない人工的な値を用いること。また、そのために設けられたカラムのこと。
https://e-words.jp/w/%E3%82%B5%E3%83%AD%E3%82%B2%E3%83%BC%E3%83%88%E3%82%AD%E3%83%BC.html
主としてNumeric・数字でナンバリングされます←Graded Quizに出ました。
Natural Key(自然キー)
Surrogate keyと合わせて頻出する語がNatural Key。どちらもprimary keyとして使われるキーのことで、天然物か養殖か的なイメージで意味の違いを認識するとわかりやすいです。
Entityを考えたときに、Nullになる可能性がなくprimary keyになれそうなAttributeが存在しているのなら、そのAttributeを使用すればいいですよね。これは元々ちょうどいいデータがあるのでNatural Key(自然キー)。
しかし、なんかちょうどいいAttributeがない、あるけど文字列なのでなんか管理しづらい…と言うときに登場するのがSurrogate Key。数字を使って採番してあげることでprimary keyを用意できます。
SQL
SQLの目的は、データベースアクセスのための共通言語を提供すること
DDL(Data Definition Language)
「データを定義する」のでcreate tableとかデータ定義のSQLのこと。
DML(Data Manupulation Language)
「データを操作」するので、データを追加したり更新したり削除するSQL。
DCL(Data Control Language)
「データをコントロール」なので、データへのアクセス権限などを操作するSQL。データ本体には触らない。
ANSI SQL
ANSIがSQLの規則などを決めています。こういうところ、Graded Quizとかに出ます。

FloatとDecimal型の違い
「浮動小数点数」とはなんぞやって、何年も放置していました。FloatとDecimalは入れられた値をどのようにデータとして保管するかが異なり、Floatはふわっとした値しか保持できないので金額とか入れると計算結果が異なってしまうことになりますよというお話。

日本人がきっと引っかかる所
お金系のカラムを作るときにはdecimal(X,2)を使うこと
お金(金額)が常に整数で表されるのは日本特有。USドルはセントを使うし、US以外の国でも大体”cent”とか”centavo”とか、なんらかの小さいお金の単位ありますよね。日本にも「銭」があるけれど為替とかでしか使わないのでうっかり「お金=整数」と思いがち。違います。お金は小数点以下第2位まで扱いましょう。
SQL Serverにはお金用の”money”というデータ型がある

SQLJとは
Javaを拡張して作られた、JavaにSQLを組み込む方法を定めたISO標準。コンパイルする前にプリプロセッサで変換しなければならない。
ODBC(Open Database Connectivity)とは
ODBCが何の略か?というクイズも出たので「Connectivityだ」というとこを覚えること。データベースへのアクセスを可能にするやつです。
JDBC(Java Database Connectivity)
やけにJDBCについても聞かれます。実際に使ったことのない方は想像しにくいのでは…?と思います。
Javaを使う方は見たことあるであろうJDBC。APIで、これを使うことでJavaアプリからデータベースのデータにアクセスできます。
急にSQLServer使えとか言われる
課題で使うデータベースの元をもらえるが、SQLServerもしくはOpen Office Base用となっている。
MySQLでやりました

ON PRIMARYって何?
SQLServerでテーブルを配置する場所のグループ化ができて、ON PRIMARYの場合PRIMARYという名前のグループ内にテーブルが作られる
vice-versa(v.v.)
Self-Quizにてこのワードが出てきたのでメモ。「逆に,反対に,逆もまた同様」といった意味です。好きなアーティストの最近のアルバム名だったので。


コメント